・2020/06/25
 【2020年版】Jetson Nanoで StyleGANを動かして可愛い美少女のアニメ顔を大量生産する方法
【2020年版】Jetson Nanoで StyleGANを動かして可愛い美少女のアニメ顔を大量生産する方法
(【俺の嫁】Jetson Nanoで StyleGANと StyleGAN2のそれぞれで、敵対的生成ネットワーク AIでアニメ顔を生成)
Tags: [Raspberry Pi], [電子工作], [ディープラーニング]
● Jetson Nano、Jetson Xavier NXの便利スクリプト
・2020/07/03

【2020年版】NVIDIA Jetson Nano、Jetson Xavier NXの便利スクリプト
Jetsonの面倒な初期設定やミドルウェアのインストールを bashスクリプトの実行だけで簡単にできます
● Jetson Xavier NXを国内定価よりも安く買う!!ザビエル元年!!
・2020/06/27
【2020年】Jetson Xavier NX 開発者キットが安かったので衝動買いした件、標準販売価格5万円が4万4千円!
【ザビエル元年】Jetson Xavier NX 開発者キットを最安値で購入で、しかも国内在庫で注文から翌日で到着、ザビエル開封レビュー
● Jetson Nanoで StyleGANを動かして可愛い美少女のアニメ顔を大量生産する方法
Jetson Nano JetPack 4.3
Jetson Nano JetPack 4.4
Jetson Xavier NX JetPack 4.4
GAN = Generative Adversarial Networks 敵対的生成ネットワーク
StyleGAN
StyleGAN - Official TensorFlow Implementation
StyleGAN2(StyleGANの改良版)
StyleGAN2 - Official TensorFlow Implementation
手塚治虫の伝説的な作品をもとに、AI が新作漫画の制作を支援
This Waifu Does Not Exist
How we built the Waifu Vending Machine
● Jetson Nanoで StyleGAN1を動かす方法
・2020/06/25
【2020年版】NVIDIA Jetson Nanoで TensorFlowの StyleGANを動かして、顔画像を生成
NVIDIA Jetson Nano JetPack StyleGAN、敵対的生成ネットワーク AIで自然な顔画像を生成する
● Jetson Nanoで StyleGAN2を動かす方法
・2020/06/25
【2020年版】NVIDIA Jetson Nanoで StyleGANの改良版の StyleGAN2で自然な画像を生成
NVIDIA Jetson Nano JetPack StyleGAN2、敵対的生成ネットワーク AIで自然な顔画像を生成する
● Jetson Nanoで StyleGAN1を動かして可愛い美少女のアニメ顔を大量生産する方法
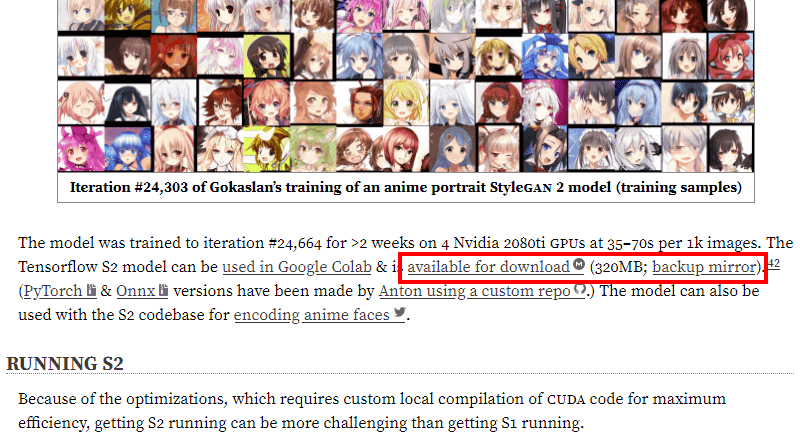
Making Anime Faces With StyleGAN
StyleGAN model used for TWDNEv1 samples as of 26 February 2019 (294MB, .pkl)
2019-02-26-stylegan-faces-network-02048-016041.pkl
をダウンロードする。
ls -l ../2019-02-26-stylegan-faces-network-02048-016041.pkl
# -rw-r--r-- 1 jetson jetson 307576240 6月 26 20:02 ../2019-02-26-stylegan-faces-network-02048-016041.pkl
・StyleGAN Making Anime Faces 2019-02-26-stylegan-faces-network-02048-016041.pkl
● Making Anime Faces With StyleGANのその他の StyleGAN model pklファイル(リンクが超絶クソわかり難い)
2019-02-26-stylegan-faces-network-02048-016041.pkl
2019-02-10-stylegan-asuka-networksnapshot-00025-007903.pkl
2019-02-10-stylegan-holofaces-networksnapshot-00015-011370.pkl
2019-03-08-stylegan-animefaces-network-02051-021980.pkl.xz
2019-04-30-stylegan-danbooru2018-portraits-02095-066083.pkl
2019-05-03-stylegan-malefaces-02107-069770.pkl
2020-05-06-arfa-stylegan2-e621-r-512-3194880.pkl.xz
● StyleGAN 1を動かして可愛い美少女のアニメ顔を 1000枚生成するデモ
pretrained_example.pyを改造して、ローカルの pklファイルを読み込む様にします。
python3 pretrained_example_anime.py
nano pretrained_example_anime.py
pretrained_example_anime.py
# Copyright (c) 2019, NVIDIA CORPORATION. All rights reserved.
#
# This work is licensed under the Creative Commons Attribution-NonCommercial
# 4.0 International License. To view a copy of this license, visit
# http://creativecommons.org/licenses/by-nc/4.0/ or send a letter to
# Creative Commons, PO Box 1866, Mountain View, CA 94042, USA.
"""Minimal script for generating an image using pre-trained StyleGAN generator."""
import os
import pickle
import numpy as np
import PIL.Image
import dnnlib
import dnnlib.tflib as tflib
import config
def main():
# Initialize TensorFlow.
tflib.init_tf()
# # Load pre-trained network.
# url = 'https://drive.google.com/uc?id=1MEGjdvVpUsu1jB4zrXZN7Y4kBBOzizDQ' # karras2019stylegan-ffhq-1024x1024.pkl
# with dnnlib.util.open_url(url, cache_dir=config.cache_dir) as f:
# _G, _D, Gs = pickle.load(f)
# Load local pickel file
# https://www.gwern.net/Faces#anime-faces
# the StyleGAN model used for TWDNEv1 samples as of 26 February 2019 (294MB, .pkl)
with open("../2019-02-26-stylegan-faces-network-02048-016041.pkl", "rb") as f:
_, _, Gs = pickle.load(f)
# _G = Instantaneous snapshot of the generator. Mainly useful for resuming a previous training run.
# _D = Instantaneous snapshot of the discriminator. Mainly useful for resuming a previous training run.
# Gs = Long-term average of the generator. Yields higher-quality results than the instantaneous snapshot.
# Print network details.
Gs.print_layers()
for i in range(1000):
print(i)
# Pick latent vector.
rnd = np.random.RandomState()
latents = rnd.randn(1, Gs.input_shape[1])
# Generate image.
fmt = dict(func=tflib.convert_images_to_uint8, nchw_to_nhwc=True)
images = Gs.run(latents, None, truncation_psi=0.7, randomize_noise=True, output_transform=fmt)
# Save image.
os.makedirs(config.result_dir, exist_ok=True)
png_filename = os.path.join(config.result_dir, 'example_anime_'+ str(i).zfill(3) +'.png')
PIL.Image.fromarray(images[0], 'RGB').save(png_filename)
if __name__ == "__main__":
main()
わぁ~~~い!! (^_^)
・Jetson Nanoで StyleGAN1を動かして可愛い美少女のアニメ顔を大量生産する方法
・Jetson Nanoで StyleGAN1を動かして可愛い美少女のアニメ顔を大量生産する方法
● Jetson Nanoで StyleGAN 2を動かして可愛い美少女のアニメ顔を大量生産する方法
PyTorchと torchvisionが必要。
StyleGAN2 - Pytorch Implementation
requirements.txt
numpy
pillow
pyyaml
requests
scipy
tensorboard
torch
torchvision
tqdm
・StyleGAN Making Anime Faces 2020-01-11-skylion-stylegan2-animeportraits-networksnapshot-024664.pkl.xz
# 2020-01-11-skylion-stylegan2-animeportraits-networksnapshot-024664.pkl.xz
xz -d 2020-01-11-skylion-stylegan2-animeportraits-networksnapshot-024664.pkl.xz
ls -l 2020-01-11-*
# -rw-r--r-- 1 jetson jetson 363989551 6月 26 21:53 2020-01-11-skylion-stylegan2-animeportraits-networksnapshot-024664.pkl
# StyleGAN2 - Pytorch Implementation
cd
git clone https://github.com/Tetratrio/stylegan2_pytorch --depth 1
cd stylegan2_pytorch
pip3 install -r requirements.txt
ls -l ../2020-01-11-*
# -rw-r--r-- 1 jetson jetson 363989551 6月 26 21:53 ../2020-01-11-skylion-stylegan2-animeportraits-networksnapshot-024664.pkl
# Generating images
# Train a network or convert a pretrained one.
# Example of converting pretrained model
python3 run_convert_from_tf.py --input=../2020-01-11-skylion-stylegan2-animeportraits-networksnapshot-024664.pkl --output skylion
# ModuleNotFoundError: No module named 'torch'
# Python 3.6 PyTorch 1.4.0
# ModuleNotFoundError: No module named 'torchvision'
# Install torchvision v0.5.0
# ModuleNotFoundError: No module named 'scipy'
# install scipy
pip3 install scipy
python3 run_convert_from_tf.py --input=../2020-01-11-skylion-stylegan2-animeportraits-networksnapshot-024664.pkl --output skylion
# Converting tensorflow models and saving them...
# Done!
# generate some images truncation_psi=1.0
python3 run_generator.py generate_images --network=skylion/Gs.pth --seeds=1,32,64,128,256,512,1024,2048 --truncation_psi=1.0
# Generating images...
# Done!
mv results results_10
ls -l results_10
# -rw-rw-r-- 1 jetson jetson 359352 6月 25 23:46 seed0001.png
# -rw-rw-r-- 1 jetson jetson 486203 6月 25 23:46 seed0032.png
# -rw-rw-r-- 1 jetson jetson 384899 6月 25 23:46 seed0064.png
# -rw-rw-r-- 1 jetson jetson 415930 6月 25 23:47 seed0128.png
# -rw-rw-r-- 1 jetson jetson 387382 6月 25 23:47 seed0256.png
# -rw-rw-r-- 1 jetson jetson 365557 6月 25 23:47 seed0512.png
# -rw-rw-r-- 1 jetson jetson 406286 6月 25 23:47 seed1024.png
# -rw-rw-r-- 1 jetson jetson 378283 6月 25 23:47 seed2048.png
# truncation_psi=0.0
python3 run_generator.py generate_images --network=skylion/Gs.pth --seeds=1,32,64,128,256,512,1024,2048 --truncation_psi=0.0
mv results results_00
# truncation_psi=0.5
python3 run_generator.py generate_images --network=skylion/Gs.pth --seeds=1,32,64,128,256,512,1024,2048 --truncation_psi=0.5
mv results results_05
# truncation_psi=1.5
python3 run_generator.py generate_images --network=skylion/Gs.pth --seeds=1,32,64,128,256,512,1024,2048 --truncation_psi=1.5
mv results results_15
# truncation_psi=2.0
python3 run_generator.py generate_images --network=skylion/Gs.pth --seeds=1,32,64,128,256,512,1024,2048 --truncation_psi=2.0
mv results results_20
# truncation_psi=3.0
python3 run_generator.py generate_images --network=skylion/Gs.pth --seeds=1,32,64,128,256,512,1024,2048 --truncation_psi=3.0
mv results results_30
# truncation_psi=5.0
python3 run_generator.py generate_images --network=skylion/Gs.pth --seeds=1,32,64,128,256,512,1024,2048 --truncation_psi=5.0
mv results results_50
# truncation_psi=-0.5
python3 run_generator.py generate_images --network=skylion/Gs.pth --seeds=1,32,64,128,256,512,1024,2048 --truncation_psi=-0.5
mv results results_05m
# truncation_psi=-1.5
python3 run_generator.py generate_images --network=skylion/Gs.pth --seeds=1,32,64,128,256,512,1024,2048 --truncation_psi=-1.5
mv results results_15m
# Generate style mixing example (matches style mixing video clip)
python3 run_generator.py style_mixing_example --network=skylion/Gs.pth --row_seeds=1,64,256,4096 --col_seeds=255,1023,2047 --truncation_psi=0.7 --output results_mix
# python3 run_generator.py style_mixing_example --network=skylion/Gs.pth --row_seeds=1,64,256,4096 --col_seeds=255,1023,2047 --truncation_psi=1.0 --output results_mix
# truncation_psi=0.0
・Jetson Nanoで StyleGAN 2を動かして可愛い美少女のアニメ顔を大量生産する方法
# truncation_psi=0.5
・Jetson Nanoで StyleGAN 2を動かして可愛い美少女のアニメ顔を大量生産する方法
# truncation_psi=1.0
・Jetson Nanoで StyleGAN 2を動かして可愛い美少女のアニメ顔を大量生産する方法
# truncation_psi=1.5
・Jetson Nanoで StyleGAN 2を動かして可愛い美少女のアニメ顔を大量生産する方法
# truncation_psi=2.0
・Jetson Nanoで StyleGAN 2を動かして可愛い美少女のアニメ顔を大量生産する方法
# truncation_psi=3.0
・Jetson Nanoで StyleGAN 2を動かして可愛い美少女のアニメ顔を大量生産する方法
# truncation_psi=5.0
・Jetson Nanoで StyleGAN 2を動かして可愛い美少女のアニメ顔を大量生産する方法
# truncation_psi=-0.5
・Jetson Nanoで StyleGAN 2を動かして可愛い美少女のアニメ顔を大量生産する方法
# truncation_psi=-1.5
・Jetson Nanoで StyleGAN 2を動かして可愛い美少女のアニメ顔を大量生産する方法
# Generate style mixing example (matches style mixing video clip)
・Jetson Nanoで StyleGAN 2を動かして可愛い美少女のアニメ顔を大量生産する方法
・Jetson Nanoで StyleGAN 2を動かして可愛い美少女のアニメ顔を大量生産する方法
・Jetson Nanoで StyleGAN 2を動かして可愛い美少女のアニメ顔を大量生産する方法
● PyTorch for Jetson Nano - version 1.5.0 now available
PyTorch for Jetson Nano - version 1.5.0 now available
PyTorch v1.4.0
JetPack 4.2 / 4.3
Python 2.7 - torch-1.4.0-cp27-cp27mu-linux_aarch64.whl
Python 3.6 - torch-1.4.0-cp36-cp36m-linux_aarch64.whl
# Install PyTorch
# Python 2.7 PyTorch 1.4.0
wget https://nvidia.box.com/shared/static/1v2cc4ro6zvsbu0p8h6qcuaqco1qcsif.whl -O torch-1.4.0-cp27-cp27mu-linux_aarch64.whl
sudo apt-get -y install libopenblas-base libopenmpi-dev
pip3 install future torch-1.4.0-cp27-cp27mu-linux_aarch64.whl
# Python 3.6 PyTorch 1.4.0
wget https://nvidia.box.com/shared/static/ncgzus5o23uck9i5oth2n8n06k340l6k.whl -O torch-1.4.0-cp36-cp36m-linux_aarch64.whl
sudo apt-get install python3-pip libopenblas-base libopenmpi-dev
pip3 install Cython
# Successfully installed Cython-0.29.20
pip3 install numpy torch-1.4.0-cp36-cp36m-linux_aarch64.whl
# Verifying The Installation
python3 -c "import torch; print (torch.__version__)"
# 1.4.0
# Install torchvision v0.5.0
cd
sudo apt-get install libjpeg-dev zlib1g-dev
# see below for version of torchvision to download
TV_VERSION=v0.5.0
git clone --branch $TV_VERSION https://github.com/pytorch/vision torchvision --depth 1
cd torchvision
sudo python3 setup.py install
# attempting to load torchvision from build dir will result in import error
cd ../
# always needed for Python 2.7, not needed torchvision v0.5.0+ with Python 3.
# (not needed) pip install 'pillow<7'
# Verifying The Installation
python3 -c "import torchvision; print (torchvision.__version__)"
# 0.5.0a0+85b8fbf
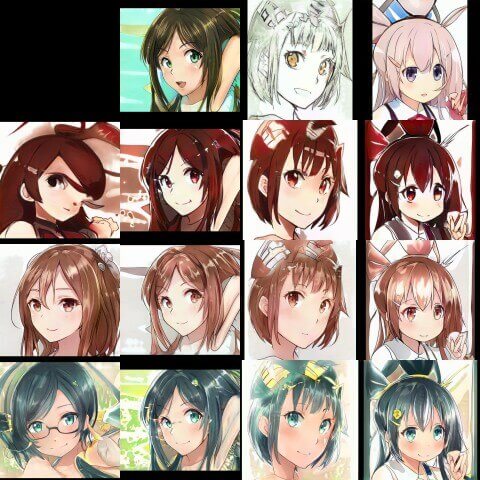
● RANDOM SAMPLES(Making Anime Faces With StyleGANから引用)
import os
import pickle
import numpy as np
import PIL.Image
import dnnlib
import dnnlib.tflib as tflib
import config
def main():
tflib.init_tf()
_G, _D, Gs = pickle.load(open("results/02051-sgan-faces-2gpu/network-snapshot-021980.pkl", "rb"))
Gs.print_layers()
for i in range(0,1000):
rnd = np.random.RandomState(None)
latents = rnd.randn(1, Gs.input_shape[1])
fmt = dict(func=tflib.convert_images_to_uint8, nchw_to_nhwc=True)
images = Gs.run(latents, None, truncation_psi=0.6, randomize_noise=True, output_transform=fmt)
os.makedirs(config.result_dir, exist_ok=True)
png_filename = os.path.join(config.result_dir, 'example-'+str(i)+'.png')
PIL.Image.fromarray(images[0], 'RGB').save(png_filename)
if __name__ == "__main__":
main()
● KARRAS ET AL 2018 FIGURES(Making Anime Faces With StyleGANから引用)
diff --git a/generate_figures.py b/generate_figures.py
index 45b68b8..f27af9d 100755
--- a/generate_figures.py
+++ b/generate_figures.py
@@ -24,16 +24,13 @@ url_bedrooms = 'https://drive.google.com/uc?id=1MOSKeGF0FJcivpBI7s63V9YHloUTO
url_cars = 'https://drive.google.com/uc?id=1MJ6iCfNtMIRicihwRorsM3b7mmtmK9c3' # karras2019stylegan-cars-512x384.pkl
url_cats = 'https://drive.google.com/uc?id=1MQywl0FNt6lHu8E_EUqnRbviagS7fbiJ' # karras2019stylegan-cats-256x256.pkl
-synthesis_kwargs = dict(output_transform=dict(func=tflib.convert_images_to_uint8, nchw_to_nhwc=True), minibatch_size=8)
+synthesis_kwargs = dict(output_transform=dict(func=tflib.convert_images_to_uint8, nchw_to_nhwc=True), minibatch_size=8, truncation_psi=0.7)
_Gs_cache = dict()
def load_Gs(url):
- if url not in _Gs_cache:
- with dnnlib.util.open_url(url, cache_dir=config.cache_dir) as f:
- _G, _D, Gs = pickle.load(f)
- _Gs_cache[url] = Gs
- return _Gs_cache[url]
+ _G, _D, Gs = pickle.load(open("results/02051-sgan-faces-2gpu/network-snapshot-021980.pkl", "rb"))
+ return Gs
#----------------------------------------------------------------------------
# Figures 2, 3, 10, 11, 12: Multi-resolution grid of uncurated result images.
@@ -85,7 +82,7 @@ def draw_noise_detail_figure(png, Gs, w, h, num_samples, seeds):
canvas = PIL.Image.new('RGB', (w * 3, h * len(seeds)), 'white')
for row, seed in enumerate(seeds):
latents = np.stack([np.random.RandomState(seed).randn(Gs.input_shape[1])] * num_samples)
- images = Gs.run(latents, None, truncation_psi=1, **synthesis_kwargs)
+ images = Gs.run(latents, None, **synthesis_kwargs)
canvas.paste(PIL.Image.fromarray(images[0], 'RGB'), (0, row * h))
for i in range(4):
crop = PIL.Image.fromarray(images[i + 1], 'RGB')
@@ -109,7 +106,7 @@ def draw_noise_components_figure(png, Gs, w, h, seeds, noise_ranges, flips):
all_images = []
for noise_range in noise_ranges:
tflib.set_vars({var: val * (1 if i in noise_range else 0) for i, (var, val) in enumerate(noise_pairs)})
- range_images = Gsc.run(latents, None, truncation_psi=1, randomize_noise=False, **synthesis_kwargs)
+ range_images = Gsc.run(latents, None, randomize_noise=False, **synthesis_kwargs)
range_images[flips, :, :] = range_images[flips, :, ::-1]
all_images.append(list(range_images))
@@ -144,14 +141,11 @@ def draw_truncation_trick_figure(png, Gs, w, h, seeds, psis):
def main():
tflib.init_tf()
os.makedirs(config.result_dir, exist_ok=True)
- draw_uncurated_result_figure(os.path.join(config.result_dir, 'figure02-uncurated-ffhq.png'), load_Gs(url_ffhq), cx=0, cy=0, cw=1024, ch=1024, rows=3, lods=[0,1,2,2,3,3], seed=5)
- draw_style_mixing_figure(os.path.join(config.result_dir, 'figure03-style-mixing.png'), load_Gs(url_ffhq), w=1024, h=1024, src_seeds=[639,701,687,615,2268], dst_seeds=[888,829,1898,1733,1614,845], style_ranges=[range(0,4)]*3+[range(4,8)]*2+[range(8,18)])
- draw_noise_detail_figure(os.path.join(config.result_dir, 'figure04-noise-detail.png'), load_Gs(url_ffhq), w=1024, h=1024, num_samples=100, seeds=[1157,1012])
- draw_noise_components_figure(os.path.join(config.result_dir, 'figure05-noise-components.png'), load_Gs(url_ffhq), w=1024, h=1024, seeds=[1967,1555], noise_ranges=[range(0, 18), range(0, 0), range(8, 18), range(0, 8)], flips=[1])
- draw_truncation_trick_figure(os.path.join(config.result_dir, 'figure08-truncation-trick.png'), load_Gs(url_ffhq), w=1024, h=1024, seeds=[91,388], psis=[1, 0.7, 0.5, 0, -0.5, -1])
- draw_uncurated_result_figure(os.path.join(config.result_dir, 'figure10-uncurated-bedrooms.png'), load_Gs(url_bedrooms), cx=0, cy=0, cw=256, ch=256, rows=5, lods=[0,0,1,1,2,2,2], seed=0)
- draw_uncurated_result_figure(os.path.join(config.result_dir, 'figure11-uncurated-cars.png'), load_Gs(url_cars), cx=0, cy=64, cw=512, ch=384, rows=4, lods=[0,1,2,2,3,3], seed=2)
- draw_uncurated_result_figure(os.path.join(config.result_dir, 'figure12-uncurated-cats.png'), load_Gs(url_cats), cx=0, cy=0, cw=256, ch=256, rows=5, lods=[0,0,1,1,2,2,2], seed=1)
+ draw_uncurated_result_figure(os.path.join(config.result_dir, 'figure02-uncurated-ffhq.png'), load_Gs(url_ffhq), cx=0, cy=0, cw=512, ch=512, rows=3, lods=[0,1,2,2,3,3], seed=5)
+ draw_style_mixing_figure(os.path.join(config.result_dir, 'figure03-style-mixing.png'), load_Gs(url_ffhq), w=512, h=512, src_seeds=[639,701,687,615,2268], dst_seeds=[888,829,1898,1733,1614,845], style_ranges=[range(0,4)]*3+[range(4,8)]*2+[range(8,16)])
+ draw_noise_detail_figure(os.path.join(config.result_dir, 'figure04-noise-detail.png'), load_Gs(url_ffhq), w=512, h=512, num_samples=100, seeds=[1157,1012])
+ draw_noise_components_figure(os.path.join(config.result_dir, 'figure05-noise-components.png'), load_Gs(url_ffhq), w=512, h=512, seeds=[1967,1555], noise_ranges=[range(0, 18), range(0, 0), range(8, 18), range(0, 8)], flips=[1])
+ draw_truncation_trick_figure(os.path.join(config.result_dir, 'figure08-truncation-trick.png'), load_Gs(url_ffhq), w=512, h=512, seeds=[91,388, 389, 390, 391, 392, 393, 394, 395, 396], psis=[1, 0.7, 0.5, 0.25, 0, -0.25, -0.5, -1])
● VIDEOS Training Montage(Making Anime Faces With StyleGANから引用)
cat $(ls ./results/*faces*/fakes*.png | sort --numeric-sort) | ffmpeg -framerate 10 \ # show 10 inputs per second
-i - # stdin
-r 25 # output frame-rate; frames will be duplicated to pad out to 25FPS
-c:v libx264 # x264 for compatibility
-pix_fmt yuv420p # force ffmpeg to use a standard colorspace - otherwise PNG colorspace is kept, breaking browsers (!)
-crf 33 # adequate high quality
-vf "scale=iw/2:ih/2" \ # shrink the image by 2x, the full detail is not necessary & saves space
-preset veryslow -tune animation \ # aim for smallest binary possible with animation-tuned settings
./stylegan-facestraining.mp4
● Interpolations(Making Anime Faces With StyleGANから引用)
import os
import pickle
import numpy as np
import PIL.Image
import dnnlib
import dnnlib.tflib as tflib
import config
import scipy
def main():
tflib.init_tf()
# Load pre-trained network.
# url = 'https://drive.google.com/uc?id=1MEGjdvVpUsu1jB4zrXZN7Y4kBBOzizDQ'
# with dnnlib.util.open_url(url, cache_dir=config.cache_dir) as f:
## NOTE: insert model here:
_G, _D, Gs = pickle.load(open("results/02047-sgan-faces-2gpu/network-snapshot-013221.pkl", "rb"))
# _G = Instantaneous snapshot of the generator. Mainly useful for resuming a previous training run.
# _D = Instantaneous snapshot of the discriminator. Mainly useful for resuming a previous training run.
# Gs = Long-term average of the generator. Yields higher-quality results than the instantaneous snapshot.
grid_size = [2,2]
image_shrink = 1
image_zoom = 1
duration_sec = 60.0
smoothing_sec = 1.0
mp4_fps = 20
mp4_codec = 'libx264'
mp4_bitrate = '5M'
random_seed = 404
mp4_file = 'results/random_grid_%s.mp4' % random_seed
minibatch_size = 8
num_frames = int(np.rint(duration_sec * mp4_fps))
random_state = np.random.RandomState(random_seed)
# Generate latent vectors
shape = [num_frames, np.prod(grid_size)] + Gs.input_shape[1:] # [frame, image, channel, component]
all_latents = random_state.randn(*shape).astype(np.float32)
import scipy
all_latents = scipy.ndimage.gaussian_filter(all_latents,
[smoothing_sec * mp4_fps] + [0] * len(Gs.input_shape), mode='wrap')
all_latents /= np.sqrt(np.mean(np.square(all_latents)))
def create_image_grid(images, grid_size=None):
assert images.ndim == 3 or images.ndim == 4
num, img_h, img_w, channels = images.shape
if grid_size is not None:
grid_w, grid_h = tuple(grid_size)
else:
grid_w = max(int(np.ceil(np.sqrt(num))), 1)
grid_h = max((num - 1) // grid_w + 1, 1)
grid = np.zeros([grid_h * img_h, grid_w * img_w, channels], dtype=images.dtype)
for idx in range(num):
x = (idx % grid_w) * img_w
y = (idx // grid_w) * img_h
grid[y : y + img_h, x : x + img_w] = images[idx]
return grid
# Frame generation func for moviepy.
def make_frame(t):
frame_idx = int(np.clip(np.round(t * mp4_fps), 0, num_frames - 1))
latents = all_latents[frame_idx]
fmt = dict(func=tflib.convert_images_to_uint8, nchw_to_nhwc=True)
images = Gs.run(latents, None, truncation_psi=0.7,
randomize_noise=False, output_transform=fmt)
grid = create_image_grid(images, grid_size)
if image_zoom > 1:
grid = scipy.ndimage.zoom(grid, [image_zoom, image_zoom, 1], order=0)
if grid.shape[2] == 1:
grid = grid.repeat(3, 2) # grayscale => RGB
return grid
# Generate video.
import moviepy.editor
video_clip = moviepy.editor.VideoClip(make_frame, duration=duration_sec)
video_clip.write_videofile(mp4_file, fps=mp4_fps, codec=mp4_codec, bitrate=mp4_bitrate)
# import scipy
# coarse
duration_sec = 60.0
smoothing_sec = 1.0
mp4_fps = 20
num_frames = int(np.rint(duration_sec * mp4_fps))
random_seed = 500
random_state = np.random.RandomState(random_seed)
w = 512
h = 512
#src_seeds = [601]
dst_seeds = [700]
style_ranges = ([0] * 7 + [range(8,16)]) * len(dst_seeds)
fmt = dict(func=tflib.convert_images_to_uint8, nchw_to_nhwc=True)
synthesis_kwargs = dict(output_transform=fmt, truncation_psi=0.7, minibatch_size=8)
shape = [num_frames] + Gs.input_shape[1:] # [frame, image, channel, component]
src_latents = random_state.randn(*shape).astype(np.float32)
src_latents = scipy.ndimage.gaussian_filter(src_latents,
smoothing_sec * mp4_fps,
mode='wrap')
src_latents /= np.sqrt(np.mean(np.square(src_latents)))
dst_latents = np.stack(np.random.RandomState(seed).randn(Gs.input_shape[1]) for seed in dst_seeds)
src_dlatents = Gs.components.mapping.run(src_latents, None) # [seed, layer, component]
dst_dlatents = Gs.components.mapping.run(dst_latents, None) # [seed, layer, component]
src_images = Gs.components.synthesis.run(src_dlatents, randomize_noise=False, **synthesis_kwargs)
dst_images = Gs.components.synthesis.run(dst_dlatents, randomize_noise=False, **synthesis_kwargs)
canvas = PIL.Image.new('RGB', (w * (len(dst_seeds) + 1), h * 2), 'white')
for col, dst_image in enumerate(list(dst_images)):
canvas.paste(PIL.Image.fromarray(dst_image, 'RGB'), ((col + 1) * h, 0))
def make_frame(t):
frame_idx = int(np.clip(np.round(t * mp4_fps), 0, num_frames - 1))
src_image = src_images[frame_idx]
canvas.paste(PIL.Image.fromarray(src_image, 'RGB'), (0, h))
for col, dst_image in enumerate(list(dst_images)):
col_dlatents = np.stack([dst_dlatents[col]])
col_dlatents[:, style_ranges[col]] = src_dlatents[frame_idx, style_ranges[col]]
col_images = Gs.components.synthesis.run(col_dlatents, randomize_noise=False, **synthesis_kwargs)
for row, image in enumerate(list(col_images)):
canvas.paste(PIL.Image.fromarray(image, 'RGB'), ((col + 1) * h, (row + 1) * w))
return np.array(canvas)
# Generate video.
import moviepy.editor
mp4_file = 'results/interpolate.mp4'
mp4_codec = 'libx264'
mp4_bitrate = '5M'
video_clip = moviepy.editor.VideoClip(make_frame, duration=duration_sec)
video_clip.write_videofile(mp4_file, fps=mp4_fps, codec=mp4_codec, bitrate=mp4_bitrate)
import scipy
duration_sec = 60.0
smoothing_sec = 1.0
mp4_fps = 20
num_frames = int(np.rint(duration_sec * mp4_fps))
random_seed = 503
random_state = np.random.RandomState(random_seed)
w = 512
h = 512
style_ranges = [range(6,16)]
fmt = dict(func=tflib.convert_images_to_uint8, nchw_to_nhwc=True)
synthesis_kwargs = dict(output_transform=fmt, truncation_psi=0.7, minibatch_size=8)
shape = [num_frames] + Gs.input_shape[1:] # [frame, image, channel, component]
src_latents = random_state.randn(*shape).astype(np.float32)
src_latents = scipy.ndimage.gaussian_filter(src_latents,
smoothing_sec * mp4_fps,
mode='wrap')
src_latents /= np.sqrt(np.mean(np.square(src_latents)))
dst_latents = np.stack([random_state.randn(Gs.input_shape[1])])
src_dlatents = Gs.components.mapping.run(src_latents, None) # [seed, layer, component]
dst_dlatents = Gs.components.mapping.run(dst_latents, None) # [seed, layer, component]
def make_frame(t):
frame_idx = int(np.clip(np.round(t * mp4_fps), 0, num_frames - 1))
col_dlatents = np.stack([dst_dlatents[0]])
col_dlatents[:, style_ranges[0]] = src_dlatents[frame_idx, style_ranges[0]]
col_images = Gs.components.synthesis.run(col_dlatents, randomize_noise=False, **synthesis_kwargs)
return col_images[0]
# Generate video.
import moviepy.editor
mp4_file = 'results/fine_%s.mp4' % (random_seed)
mp4_codec = 'libx264'
mp4_bitrate = '5M'
video_clip = moviepy.editor.VideoClip(make_frame, duration=duration_sec)
video_clip.write_videofile(mp4_file, fps=mp4_fps, codec=mp4_codec, bitrate=mp4_bitrate)
if __name__ == "__main__":
main()
● Interpolations(Making Anime Faces With StyleGANから引用)
import dnnlib.tflib as tflib
import math
import moviepy.editor
from numpy import linalg
import numpy as np
import pickle
def main():
tflib.init_tf()
_G, _D, Gs = pickle.load(open("results/02051-sgan-faces-2gpu/network-snapshot-021980.pkl", "rb"))
rnd = np.random
latents_a = rnd.randn(1, Gs.input_shape[1])
latents_b = rnd.randn(1, Gs.input_shape[1])
latents_c = rnd.randn(1, Gs.input_shape[1])
def circ_generator(latents_interpolate):
radius = 40.0
latents_axis_x = (latents_a - latents_b).flatten() / linalg.norm(latents_a - latents_b)
latents_axis_y = (latents_a - latents_c).flatten() / linalg.norm(latents_a - latents_c)
latents_x = math.sin(math.pi * 2.0 * latents_interpolate) * radius
latents_y = math.cos(math.pi * 2.0 * latents_interpolate) * radius
latents = latents_a + latents_x * latents_axis_x + latents_y * latents_axis_y
return latents
def mse(x, y):
return (np.square(x - y)).mean()
def generate_from_generator_adaptive(gen_func):
max_step = 1.0
current_pos = 0.0
change_min = 10.0
change_max = 11.0
fmt = dict(func=tflib.convert_images_to_uint8, nchw_to_nhwc=True)
current_latent = gen_func(current_pos)
current_image = Gs.run(current_latent, None, truncation_psi=0.7, randomize_noise=False, output_transform=fmt)[0]
array_list = []
video_length = 1.0
while(current_pos < video_length):
array_list.append(current_image)
lower = current_pos
upper = current_pos + max_step
current_pos = (upper + lower) / 2.0
current_latent = gen_func(current_pos)
current_image = images = Gs.run(current_latent, None, truncation_psi=0.7, randomize_noise=False, output_transform=fmt)[0]
current_mse = mse(array_list[-1], current_image)
while current_mse < change_min or current_mse > change_max:
if current_mse < change_min:
lower = current_pos
current_pos = (upper + lower) / 2.0
if current_mse > change_max:
upper = current_pos
current_pos = (upper + lower) / 2.0
current_latent = gen_func(current_pos)
current_image = images = Gs.run(current_latent, None, truncation_psi=0.7, randomize_noise=False, output_transform=fmt)[0]
current_mse = mse(array_list[-1], current_image)
print(current_pos, current_mse)
return array_list
frames = generate_from_generator_adaptive(circ_generator)
frames = moviepy.editor.ImageSequenceClip(frames, fps=30)
# Generate video.
mp4_file = 'results/circular.mp4'
mp4_codec = 'libx264'
mp4_bitrate = '3M'
mp4_fps = 20
frames.write_videofile(mp4_file, fps=mp4_fps, codec=mp4_codec, bitrate=mp4_bitrate)
if __name__ == "__main__":
main()
● COPYRIGHT(Making Anime Faces With StyleGANから引用に関して)
Per the copyright point above, all my generated videos and samples and models are released under the CC-0 (public domain equivalent) license. Source code listed may be derivative works of Nvidia’s CC-BY-NC-licensed StyleGAN code, and may be CC-BY-NC.
Tags: [Raspberry Pi], [電子工作], [ディープラーニング]
●関連するコンテンツ(この記事を読んだ人は、次の記事も読んでいます)
【2020年版】NVIDIA Jetson Nano、Jetson Xavier NXの便利スクリプト
Jetsonの面倒な初期設定やミドルウェアのインストールを bashスクリプトの実行だけで簡単にできます
【2020年】Jetson Xavier NX 開発者キットが安かったので衝動買いした件、標準販売価格5万円が4万4千円!
【ザビエル元年】Jetson Xavier NX 開発者キットを最安値で購入で、しかも国内在庫で注文から翌日で到着、ザビエル開封レビュー
【2020年版】NVIDIA Jetson用に最新の CMake 3.17.3をビルドしてインストールする方法
2020年の JetPack 4.4になっても CMakeのバージョンが 3.10.2と古く OpenPoseのビルドでエラー発生の原因
【2020年版】NVIDIA JetPack 4.4 DP Developer Previewで OpenPoseのビルドエラーの対策方法
Jetson Nano、Jetson Xavier NX 開発者キット + JetPack 4.4 DPで OpenPoseをビルドする手順
Jetson Nano、Jetson Xavier NX 開発者キット TensorFlow on Jetson Platform
NVIDIA Jetson Nano、Jetson Xavier NX Developer TensorFlow on Jetson Platform
NVIDIA Jetson Nano 開発者キットを買ってみた。メモリ容量 4GB LPDDR4 RAM
Jetson Nanoで TensorFlow PyTorch Caffe/Caffe2 Keras MXNet等を GPUパワーで超高速で動かす!
【2020年版】NVIDIA Jetson Nanoの初期設定、最高速で動かす設定、空きメモリを増やす方法等
2020年の JetPack 4.4になっても nvccのパスがデフォルトで通って無いとか、初期設定が必要です
【2020年版】NVIDIA Jetson Nano JetPackのバージョン情報まとめ、JetPack 4.4は仕様変更の影響が大きい
最新の JetPackでは 2019年当時の殆どの記事の内容がそのままではエラーが出て動かない様になりました
【2020年版】NVIDIA Jetson Nano対応の FFmpegをビルドする手順
NVIDIA Jetson Nano対応の FFmpegをビルドする手順、x264と x265にも対応
【2020年版】NVIDIA Jetson Nano対応の OpenPoseをビルドする手順
NVIDIA Jetson Nano対応の OpenPoseをビルドする手順
NVIDIA Jetson Nanoで OpenCV 3をビルドしてインストールする方法、NVCaffe等の OpenCV 4未対応を動かす
NVIDIA Jetson Nanoに「古い」 OpenCV 3.4.10をビルドしてインストールする方法
NVIDIA Jetson Nanoで Visual Studio Code Open Sourceをビルドして実行する
NVIDIA Jetson Nanoで VSCode Open Source Code - OSSをビルドして実行する、1.35.0
【2020年版】NVIDIA Jetson Nanoで TensorFlowの StyleGANを動かして、顔画像を生成
NVIDIA Jetson Nano JetPack StyleGAN、敵対的生成ネットワーク AIで自然な顔画像を生成する
【2020年版】NVIDIA Jetson Nanoで StyleGANの改良版の StyleGAN2で自然な画像を生成
NVIDIA Jetson Nano JetPack StyleGAN2、敵対的生成ネットワーク AIで自然な顔画像を生成する
【メモリ8GB】Raspberry Pi 4 Model B 8GBを KSYで最安値で購入。ベンチマークレビュー
【技適取得】ラズパイ4B 8GBモデルを入手。従来の Pi3、Pi3B+と速度比較
【Vulkan】Raspberry Pi 4 Model Bで Vulkanドライバをビルドして 3Dグラフィックのデモを動かす
【v3dv】ラズパイ4Bで Vulkan APIを動かす、VK_ICD_FILENAMES broadcom_icd.armv7l.json
PIP機能付きの 4K対応の 4入力 1出力の HDMIセレクターを買ってみた、HDMI機器が複数有る場合に便利
ピクチャ イン ピクチャ機能付き 4K入力対応の 4入力 1出力 HDMI切り換え機 HDSFX0401P
EDID保持機能付きの 4K対応の 4入力 2出力の マトリックス切り替え HDMIセレクター、液晶画面 2台と使用で最強
TESmart HMA0402A30 マトリックス切り替えで液晶画面 2台に接続できて更に EDID保持の便利機能付き HDMI切り換え機
[HOME]
|
[BACK]
リンクフリー(連絡不要、ただしトップページ以外は Web構成の変更で移動する場合があります)
Copyright (c)
2020 FREE WING,Y.Sakamoto
Powered by 猫屋敷工房 & HTML Generator
http://www.neko.ne.jp/~freewing/raspberry_pi/nvidia_jetson_nano_tensorflow_stylegan_pretty_anime_face/